
本文转自徐飞翔的“【Debug危机系列】 记一次opencv相关的debug过程”
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明
本次bug涉及的api: cv2.cvtColor() , cv2.imencode()。以此为序章,让我们开始。
本次的bug是在笔者基于内部框架开发的过程中出现的,大概背景是:
当训练完某个模型后(称之为离线模型),需要将其部署在该框架上,该框架可以对全库的视频进行特征提取(称之为在线模型)。模型采用paddle进行训练,期望中对于同个输入视频,离线模型和在线模型的特征应该非常接近(误差小于 )。然而在初步测试中,却发现diff非常大(大概是
之间),不符合预期。进而进行debug。
首先在不涉密的前提下,简单对我们离线训练,和在线部署的框架的流程进行介绍。模型在训练好后,因某些原因,首先会在离线模型处理流程中进行打分验证,打分验证后进行在线部署对所有数据生效。如Fig 1.1所示,离线模型首先对视频url进行预处理,然后下载视频,并且从中抽帧10帧,为了进行网络传输方便,同时在离线处理中会对这10帧进行序列化。序列化的方式是将每一帧图像编码成base64,并且多帧之间通过\1隔开,从而将10帧图片编码成了字符串,通过网络传输给模型计算服务。模型计算服务首先对收到的字符串进行反序列化,并且将恢复出的图像进行预处理,包括resize()和BGR2RGB,像素Normalization。随后送给模型进行计算,然后返回特征入库即可。离线模型由于是出于验证效果的目的设计的,因此通常本地就能运行。这里指的标准化是对像素减去均值,除以方差,如下所示。
# process of pixel normalization
img_mean = np.array([0.485, 0.456, 0.406]).reshape(3, 1, 1)
img_std = np.array([0.229, 0.224, 0.225]).reshape(3, 1, 1)
# mean 和 std来自于对imagenet的统计,见引用[1]
imgs = get_imgs() # 此时imgs是array组成的列表
np_imgs = np.array(imgs) / 255 # shape (10, 3, 224, 224) 其中10是帧数,将数值范围缩放到[0,1]之间
np_imgs -= img_mean
np_imgs /= img_std
其中离线计算中,对数据进行序列化的过程如下代码所示:
# image serialization
frame_list = []
for frame in frames:
frame_str = cv2.imencode('.jpg?x-oss-process=image/watermark,g_center,image_YXJ0aWNsZS9wdWJsaWMvd2F0ZXJtYXJrLnBuZz94LW9zcy1wcm9jZXNzPWltYWdlL3Jlc2l6ZSxQXzQwCg==,t_20', frame)[1].tostring()
frame_b64 = base64.b64encode(frame_str)
frame_list.append(frame_b64)
video_str = '\1'.join(map(str, frame_list))
在线模型计算也是类似的,先对url进行预处理,然后视频下载,抽10帧。此时有点不同的是,会先将抽帧好后的原始图片(还未进行任何预处理)存在本地文件夹内,然后在视频帧的预处理阶段,会重新从该文件夹内加载图片,并且进行BGR2RGB和resize预处理。随后进行序列化发给模型计算服务,同样进行拆包,预处理(此处的预处理只剩下像素Normalization生效),然后计算特征入库。
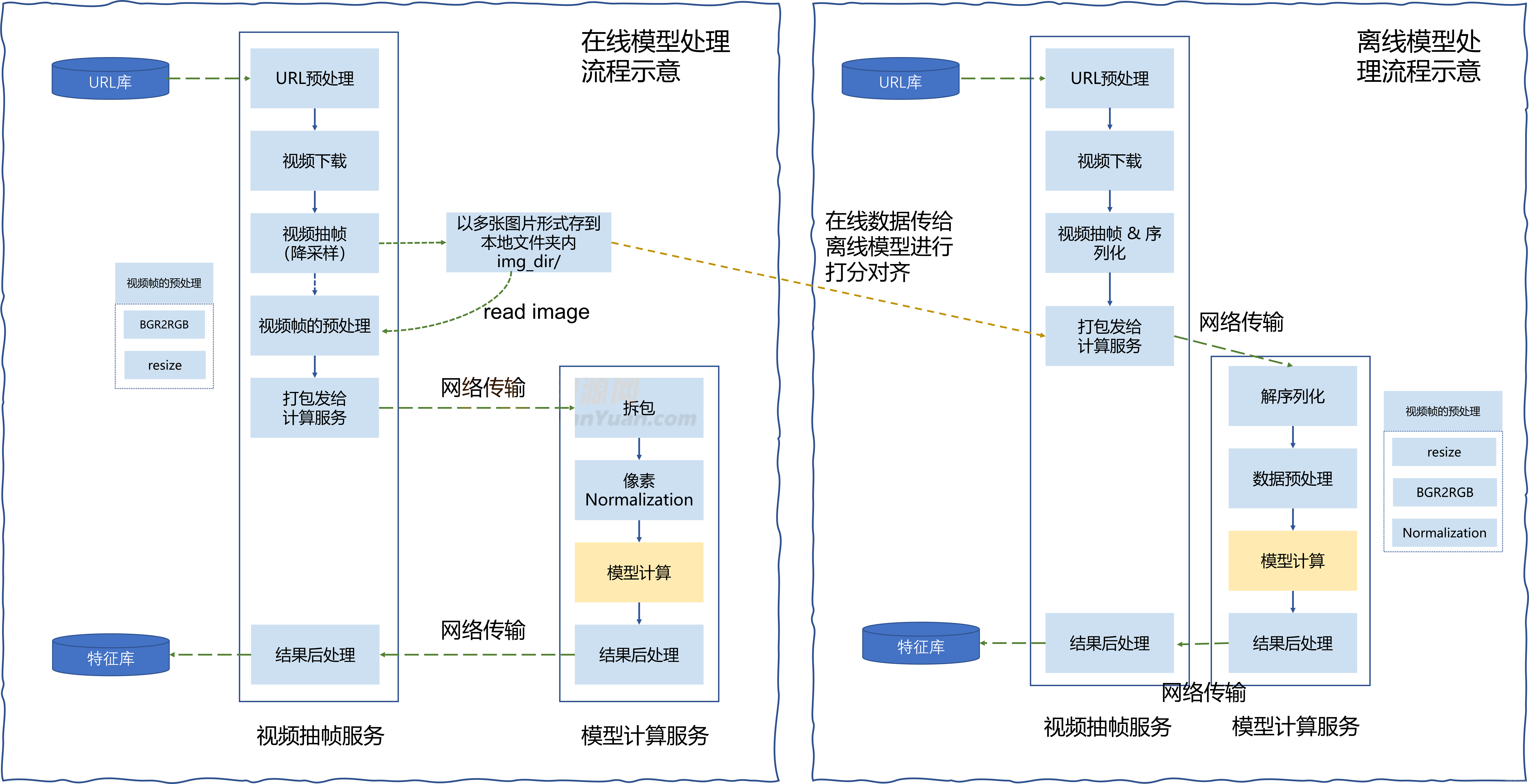
Fig 1.1 在线模型处理流程与离线模型处理流程。
当我们的模型特征在离线阶段进行过效果验证后,我们进行在线模型的开发,并且期望离线和在线的特征打分能对的上,此时会将转存到本地文件夹img_dir的10张图片作为标准,想办法把它传给离线模型打分,然后和在线模型打分进行对比即可。为了从本地的img_dir中将视频帧序列化发送给离线模型进行打分,需要模拟离线序列化,我是这样做的:
frames_name = get_img_dir_names()
ret_list = []
for frame_name in frames_name:
img = cv2.imread(frame_name, cv2.IMREAD_COLOR)
img = cv2.resize(img, (224, 224), interpolation=cv2.INTER_LINEAR) # bug 1
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # bug 2
frame_str = cv2.imencode('.jpg?x-oss-process=image/watermark,g_center,image_YXJ0aWNsZS9wdWJsaWMvd2F0ZXJtYXJrLnBuZz94LW9zcy1wcm9jZXNzPWltYWdlL3Jlc2l6ZSxQXzQwCg==,t_20', frame)[1].tostring()
frame_b64 = base64.b64encode(frame_str)
frame_b64 = frame_b64.decode()
ret_list.append(frame_b64)
video_str = '\1'.join(map(str, ret_list))
后坑也就处在这短短的模拟输入的代码上,当较大的打分diff出现的时候,我进行整个流程二分式的排错,然后定位到在离线流程的解序列化和预处理阶段就已经发生了图片通道的逆序,这意味着传输进来的图片通道是错误的,最后才发现cv2.imread()本来对于输入,期望是BGR序的,所以在后续的流程中才会用cvtCOlor()将其转化成RGB序。而我在模拟输入的时候就将其转换成了RGB序,因此出现打分的较大差别,此时需要将代码段的bug 2去除。解完该处的bug后,整套系统还是有1e-3左右的diff,这个diff说大不大,对最后特征上线应用可能影响不大,但是也不符合我的预期范围,为了更为精准的跟踪整个过程,我将在线不同步骤的数据dump下来,在对应的离线步骤进行插入进行“从下到上”的debug。当然,最后的debug点还是收敛到了我的离线输入模拟代码,主要是bug 1处。
简单看这块没有啥问题,我先进行图片的resize,然后进行序列化传输到计算服务进行打分。即便计算服务中的数据预处理模块中已经有了resize操作,但是由于resize的尺寸相同,第二resize是不会生效的(为此我还进行了验证,的确是不会生效的)。但是我们注意到resize图片之后,还进行了图片编码!!! 也就是cv2.imencode(),即便原图片就是.jpg?x-oss-process=image/watermark,g_center,image_YXJ0aWNsZS9wdWJsaWMvd2F0ZXJtYXJrLnBuZz94LW9zcy1wcm9jZXNzPWltYWdlL3Jlc2l6ZSxQXzQwCg==,t_20格式,在imecode()中仍然会对其进行jpg编码然后载入内存中,而这个过程前后对于图片来说是有diff的,从以下代码即可验证
img = get_img()
print("img before encode [%f]" % img.mean())
img_encode = encode(img) # 采用imencode进行编码载入内存,并且转成base64字符串
img_recover = decode(img_encode) # 进行解码
print("img after decode [%f]" % img_recover.mean())
我们会发现编码前后图片均值是不同的… 因此我们不能在编码前进行resize,而应该将resize延迟到模型计算中进行,需要将代码bug 1去除。
体会本次的bug其实并不会影响正式上线后的效果,因为本次只是对离线在线的打分对齐进行验证,而我的bug出现在验证过程中,并不是离线模型或者在线模型本身的问题。但是这个会影响我对模型的预期,由于离线在线的整个pipeline较长,而且需要模拟离线模型的输入,在此过程中一旦出现diff,要定位起来比较困难。之前组内有同学提到不同opencv版本的resize函数有diff,我也没有验证过但放在心上了。因此在本次debug过程中,我一直怀疑是不是不同机器,不同opencv版本的resize导致的diff,而没有彻底观测二分debug的原则进行每个阶段的排查,这里在错误的方向花了不少debug时间。后续对于这种没有验证过的结论,首先需要在google进行相关问题搜索,是否有人出现过相似问题,如果没有再想办法抽离出该结论进行小试验,如果试验证明结论是错误的,赶紧将方向转到其他debug路线上。
Reference
[1]. https://stackoverflow.com/questions/58151507/why-pytorch-officially-use-mean-0-485-0-456-0-406-and-std-0-229-0-224-0-2, 《Why Pytorch officially use mean=[0.485, 0.456, 0.406] and std=[0.229, 0.224, 0.225] to normalize images?》